Współczesny konsument jest wciąż bombardowany komunikatami. Konkurencja o coraz krótsze okresy uwagi jest krwawa i liczy się w niej wykorzystanie każdej możliwej przewagi. W jaki sposób data science może pomóc w skutecznej walce o dotarcie z przekazem marki do konsumentów? Poznaj szczegóły wykorzystania uczenia maszynowego w komunikacji marketingowej.
Jak komunikacja marketingowa wyglądała kiedyś?
W pierwszych latach komercyjnego internetu, kiedy dopiero rozpoczynało się wykorzystywanie e-maili w komunikacji marketingowej, zadanie było w miarę proste. Nie było jeszcze dużej konkurencji , działał efekt świeżości, konsumenci byli bardziej skłonni otwierać i czytać wiadomości. Można powiedzieć, że do sukcesu wystarczało samo posiadanie bazy adresowej i realizowanie jakichkolwiek wysyłek. Wystarczające było stosowanie prostego modelu nieco żartobliwie określanego jako „Wszystko Każdemu Zawsze” (WKZ). Nazwa odzwierciedla tendencję do wysyłania każdej przygotowanej komunikacji do całej dostępnej bazy adresatów. Strategia ta opierała się na założeniu, że każda wysłana wiadomość w jakimś stopniu zwiększa prawdopodobieństwo pozytywnej reakcji, a koszt wysłania każdej dodatkowej wiadomości jest bliski zeru. W przypadku smsów koszt mógł być oczywiście czynnikiem ograniczającym wolumen wysyłanych wiadomości. W bardzo wielu sytuacjach radzono sobie z tym jednak w prosty sposób, proporcjonalnie zmniejszając wolumen tak, żeby wyczerpać, ale nie przekroczyć przyznanego budżetu.
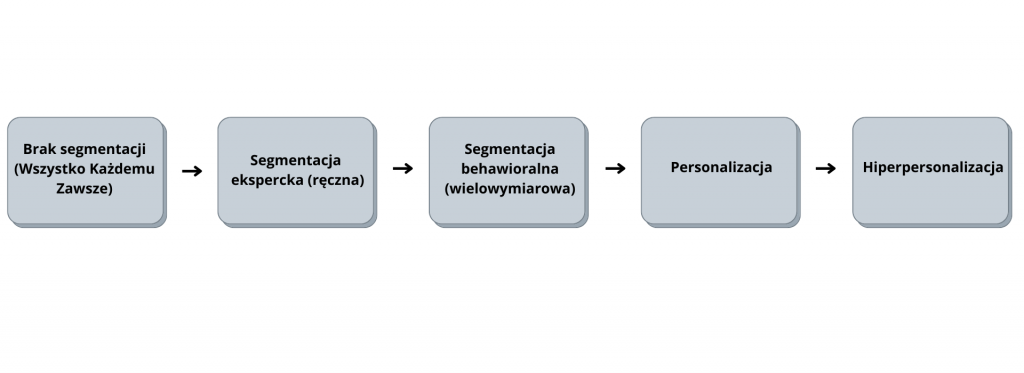
Od braku segmentacji do hiperpersonalizacji
Sytuacja zaczęła zmieniać się wraz ze wzrostem liczby marek wykorzystujących kanały email i sms w komunikacji. Skrzynki odbiorcze konsumentów zaczęły „pękać w szwach”. Liczby otrzymywanych wiadomości przekraczały możliwości percepcji. Komunikacja marketingowa w wielu przypadkach zaczęła być postrzegana jako niechciana („spam”). Przyczyniło się do tego także powszechne stosowanie wspominanego wcześniej modelu WKZ. Rolę odgrywały przede wszystkim brak dostosowania treści do specyfiki konsumenta oraz zbyt częste wysyłki. Pozornie zerowy koszt wysyłki („najwyżej klient nie otworzy”) nie zachęcał do inwestowania czasu i środków w precyzję targetowania. W kalkulacjach nie brano jednak pod uwagę, że reakcją konsumenta na nadmiar komunikatów będzie stopniowe uodparnianie się na przekaz i spadające zainteresowanie otwieraniem wiadomości.
Pierwszym krokiem na drodze wyjścia z sytuacji było przyznanie, że konsumenci w bazie nie są jednakowi. Mają różne potrzeby i cechy. W związku z tym wysyłana do nich treść powinna być odpowiednio dostosowana. Rozpoczęto segmentować bazę. Dominowała segmentacja ręczna w oparciu o wiedzę ekspercką i zdefiniowane z góry segmenty. W tym podejściu liczba możliwych do zastosowania cech konsumenta i segmentów była ograniczona ludzkimi możliwościami.
Zwiększająca się liczba danych
W raz ze zwiększaniem się wolumenu i zakresu danych na temat konsumenta, jakie gromadzone były w bazach, otwierały się nowe możliwości. Nowe dane w połączeniu z rosnącą mocą obliczeniową i zaawansowaniem algorytmów uczenia maszynowego pozwoliły na zwiększenie liczby wykorzystywanych w segmentacji cech. Segmentacja przybrała charakter behawioralny. Dzięki dużej liczbie analizowanych wymiarów, mogła uwzględnić bardziej złożone aspekty zachowania konsumenta i jego relacji z marką. Zastosowanie uczenia maszynowego pozwoliło też na wyróżnienie i przeanalizowanie większej liczby segmentów. To z kolei przekładało się na większą spójność wyłanianych grup i pozwalało na lepsze dopasowanie komunikacji do odbiorcy.
Kolejnym etapem w opisywanej ewolucji było wykorzystanie modeli predykcyjnych do bardziej spersonalizowanego dopasowania komunikacji na poziomie indywidualnego konsumenta. Wcześniej segmentacja pozwalała na operowanie na poziomie grup konsumentów. Różne segmenty mogły otrzymywać inny komunikat w innym momencie, ale wszyscy odbiorcy należący do danego segmentu otrzymywali to samo. Wraz ze wzrostem poziomu zaawansowania segmentacji liczba segmentów mogła być większa, a konsumenci przypisani do nich z większą dokładnością. Poziom generalizacji był jednak wciąż wysoki i pole do poprawy precyzji działań nadal duże. Zastosowanie predykcyjnych modeli scoringowych stanowiło istotny krok na przód. Model przewidywał prawdopodobieństwo zainteresowania każdego indywidualnego konsumenta przedmiotem danej komunikacji. Mógł to być na przykład konkretny produkt, grupa produktowa, oferta promocyjna.
Uczenie maszynowe
Na podstawie danych o zachowaniach konsumentów zgromadzonych w bazie, algorytm uczył się wzorców. W oparciu o nie, był w stanie przewidzieć, który z palety dostępnych komunikatów w największym stopniu pozytywnie wpłynie na konkretnego klienta. Dzięki temu każdy odbiorca w bazie, bez względu na przypisany do niego segment, mógł otrzymać najbardziej odpowiednią treść. Jeśli dla żadnego z zaplanowanych wariantów model nie prognozował wystarczająco wysokiego zainteresowania konsumenta, mógł on zostać wyłączony z danej wysyłki. Pozwalało to na dużą skalę wprowadzić w życie zasadę, że jeśli nie mamy dla ciebie w tym momencie niczego ciekawego do powiedzenia, to lepiej pomilczmy. Dzięki temu konsument mógł mieć poczucie, że dostaje tylko wiadomości dla niego istotne. Nie brakuje przykładów projektów, w których wdrożone zostały tego typu modele predykcyjne. Dzięki temu percepcja odbiorców zmieniła się z „przestańcie wysyłać mi ten spam” na „kiedy dostanę kolejny newsletter”.
Wykorzystanie uczenia maszynowego w komunikacji marketingowej
Opisane modele scoringowe, w połączeniu z zespołem dodatkowych, jeszcze bardziej zaawansowanych modeli pozwalają posunąć personalizację o kolejny krok ku tak zwanej hiperpersonalizacji. Cechuje się ona między innymi:
– precyzyjnym dostosowaniem momentu wysyłki. Każdy konsument może mieć przypisany idealny moment (w rozumieniu godziny, dnia tygodnia, czasu od poprzedniej wysyłki, czasu od poprzedniej wizyty na stronie etc.).
– Doborem najlepszego kanału komunikacji w powiązaniu z idealnym momentem wysyłki.
– Doborem najlepszej kombinacji zastosowanych kanałów (konsument może przykładowo najlepiej reagować na połączenie emaila i wysłanego dwa dni później smsa).
– Możliwością indywidualizacji elementów kontentu (np. dobranie odpowiednich słów w temacie, wybór najlepszego zdjęcia i innych elementów graficznych.
– Dynamicznym dopasowaniem komunikatu do kontekstu konsumenta w czasie rzeczywistym. Inny komunikat i kanał będzie adekwatny, kiedy konsument zostanie zlokalizowany w galerii handlowej, a inny, kiedy w autobusie w drodze do pracy.
1) warte podkreślenia jest, że wszystkie wymienione wyżej personalizacje odbywają się na podstawie wzorców zachowań, których modele „nauczyły się”, obserwując konsumentów a nie na deklaracjach konsumentów. Klient może deklarować, że chciałby otrzymywać mailingi w dni robocze rano. W rzeczywistości największą skuteczność mają mailingi wysłane do niego w soboty wieczorem.
2) Maksymalna moc opisywanego rozwiązania bierze się z synergii poszczególnych submodeli systemu. Optymalny moment dla danego konsumenta będzie różny dla różnych kanałów. Optymalna sekwencja i kombinacja kanałów może być zależna od charakteru komunikowanej promocji. Wreszcie optymalny tekst komunikatu może zależeć od kanału i lokalizacji użytkownika.
Konkurencja o uwagę konsumentów będzie rosnąć wraz z pojawianiem się kolejnych kanałów kontaktu, a także zwiększa się wraz ze wzrostem świadomości marketerów, co do narzędzi, jakie mogą być w ich dyspozycji. Warto zadać sobie pytanie, na jakim etapie opisywanej ewolucji jest nasza organizacja i co możemy zrobić, żeby wykonać kolejny krok, by zyskać dodatkową przewagę i nie pozwolić prześcignąć się konkurencji.