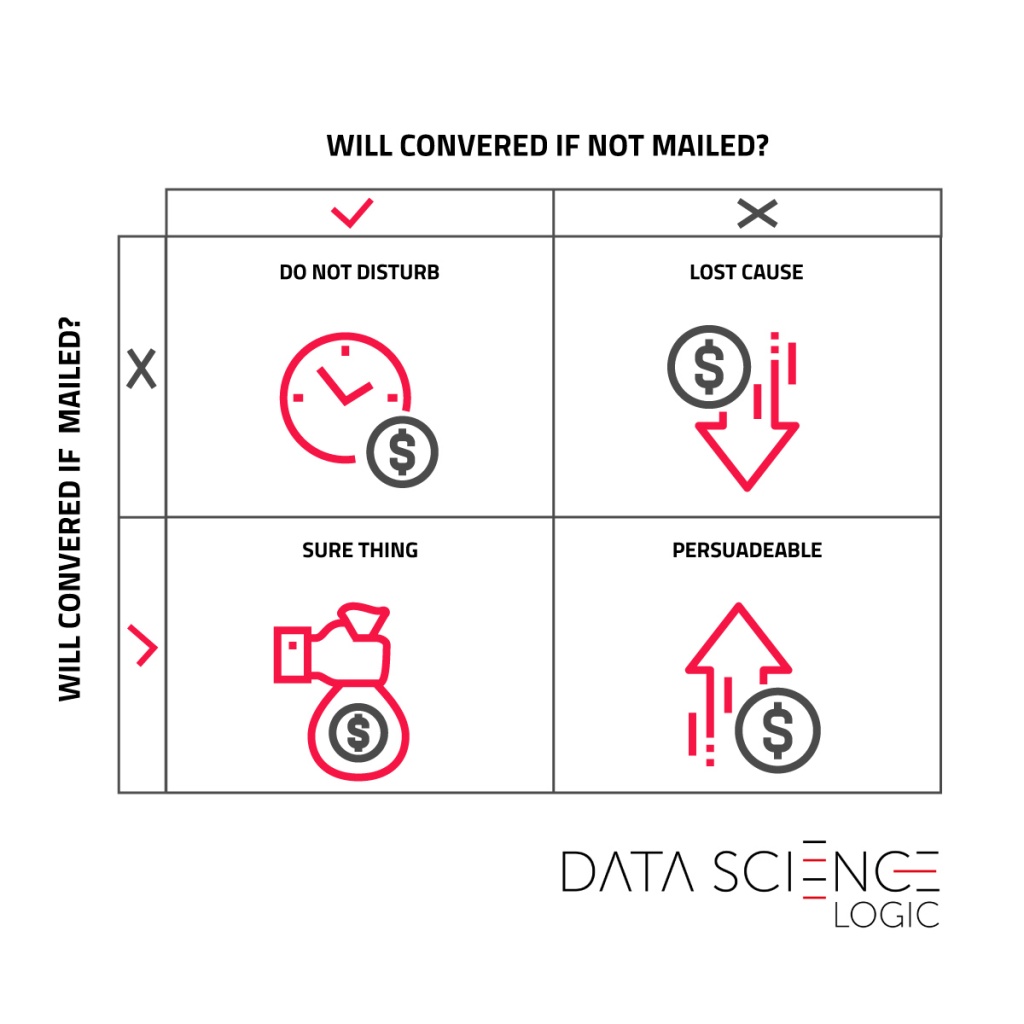
Pozyskanie nowego klienta jest droższe niż utrzymanie dotychczasowego
To nie tylko powtarzany często marketingowy truizm. Badania cytowane w Harvard Business Review dowodzą, że koszt pozyskania nowego klienta może być od 5 do nawet 25 razy wyższy niż w stosunku do kosztu utrzymania klienta w zależności od branży. A poprawa wskaźnika retencji o zaledwie 5% może przełożyć się nawet na 25-procentowy wzrost zysków. Jak więc walczyć z utratą klientów i podwyższać retencję? W jaki sposób analiza danych może nam w tym pomóc?
Odchodzenie klientów (ang. churn lub attrition) jest zjawiskiem nieuniknionym i niemożliwe jest jego całkowite wyeliminowanie. Część klientów bez względu na podejmowane wobec nich działania odchodzi. Przykładowo dlatego, że przeprowadza się poza obszar działania firmy lub przestaje być grupą docelową i nie potrzebuje już dłużej naszego produktu. Pozostała część jednak rezygnuje, wybierając ofertę konkurencji. Tym odejściom można by było zapobiec. Gdyby zostały podjęte działania. Właściwe działania, we właściwym momencie. Kluczem do tego są:
- przewidzenie ryzyka odejścia klienta z odpowiednią trafnością i wyprzedzeniem
- zrozumienie czynników, które wpływają na ryzyko utraty klienta
Rozwiązaniem obu problemów może być antychurnowy model predykcyjny zbudowany przy pomocy uczenia maszynowego. Model taki zdolny jest do przewidywania ryzyka utraty konkretnego klienta. Identyfikuje przy tym najważniejsze czynniki związane ze wzrostem tego ryzyka tak w wymiarze ogólnym dla całej bazy klientów, jak i indywidualnym dla pojedynczego klienta w jego specyficznej sytuacji. Tego rodzaju modele predykcyjne mogą wykorzystywać dowolną definicję „churn” i znajdują zastosowanie zarówno w biznesach, gdzie odejście klienta jest wyraźnie zaznaczone w czasie (np. wygaśnięcie/wypowiedzenie umowy), jak i takich, gdzie klient po prostu przestaje powracać i dokonywać kolejnych zakupów.
Najważniejsze czynniki determinujące odejście klienta
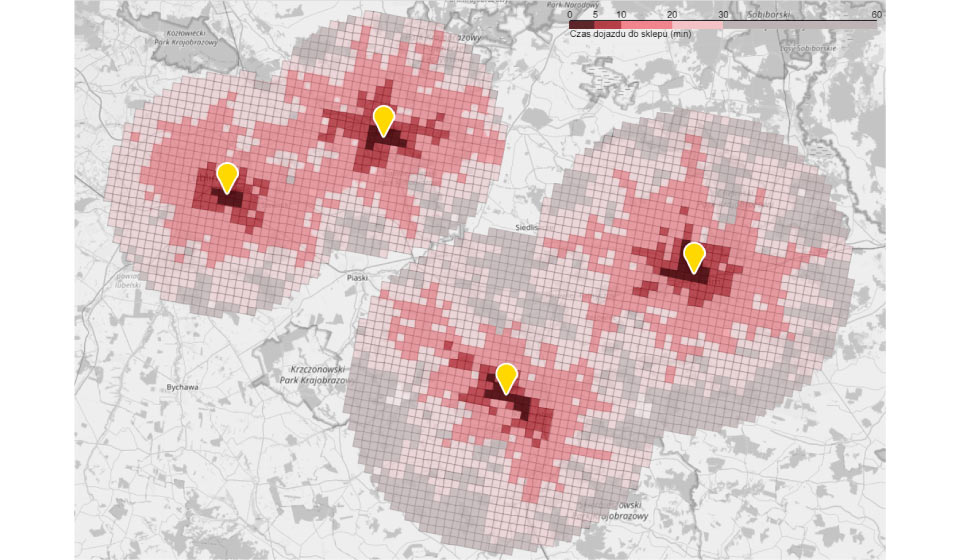
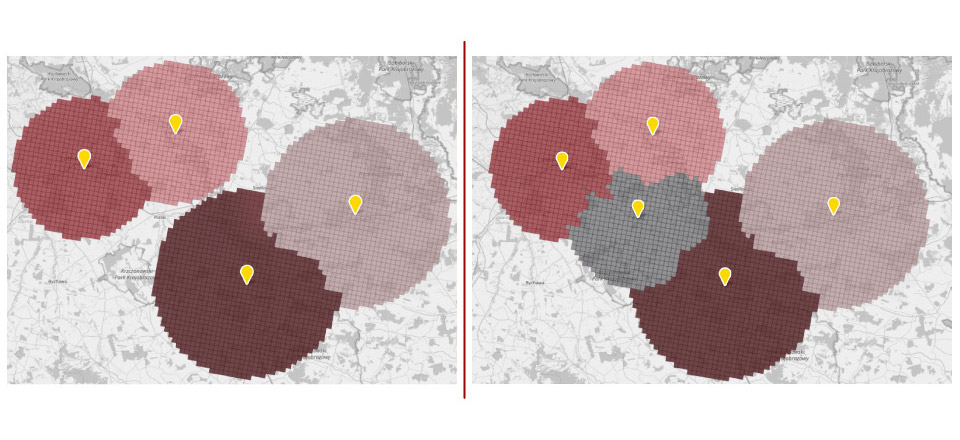
Jak już wspomnieliśmy model predykcyjny pomaga zidentyfikować najważniejsze czynniki wpływające na zagrożenie odejściem klienta. Wykresy poniżej pochodzą z rzeczywistego modelu predykcyjnego zbudowanego na bazie jednego z kontrahentów Data Science Logic. Zmienione zostały jedynie niektóre nazwy zmiennych (w tym nazwy kategorii produktowych). Warto podkreślić, że jest to branża cechująca się relatywnie niską częstotliwością zakupów (przeciętnie kilka razy w roku) i dużą rotacją klientów.
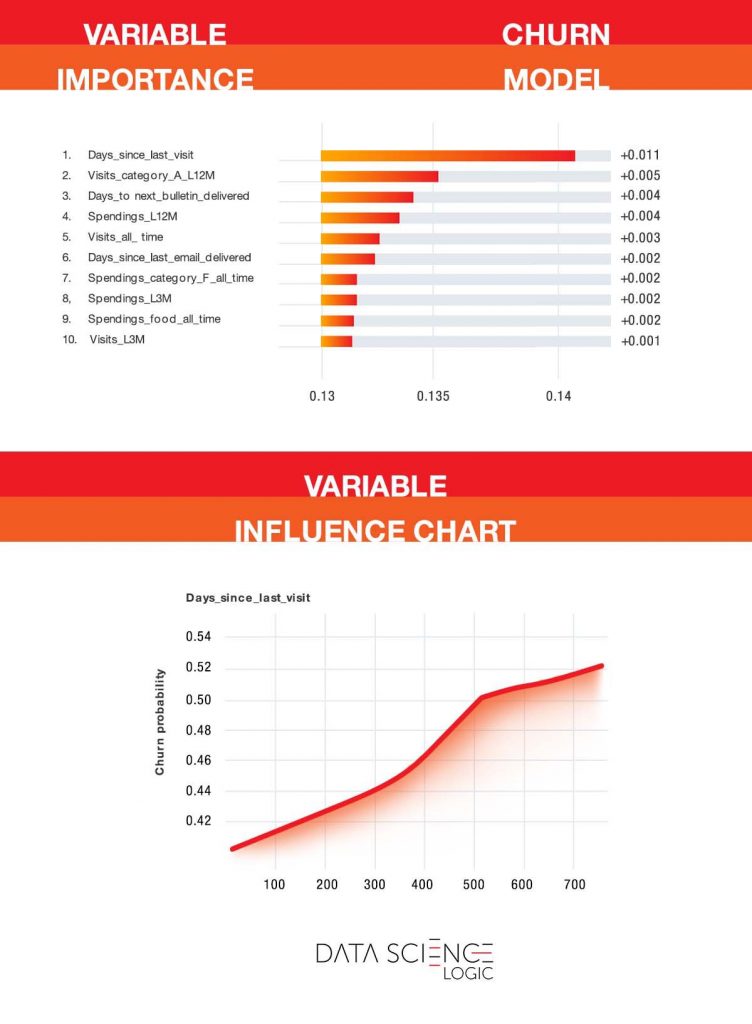
Wykres na górze pokazuje cechy klientów, które w największym stopniu wyjaśniają prawdopodobieństwo odejścia. Jak widać kluczową zmienną jest liczba dni od ostatniej wizyty z zakupem. Nie jest to zaskakujące. Im dłużej nie było klienta, tym mniejsza szansa, że wróci. Model pozwala jednak precyzyjnie określić, w którym momencie wzrost ryzyka jest największy i kiedy trzeba podjąć zdecydowane działania. Jak widać na dolnym wykresie do około 365 dni ryzyko rośnie liniowo. Po przekroczeniu jednego roku nieaktywności, krzywa ryzyka staje się bardziej stroma. Jest to już ostatni moment na podjęcie kampanii antychurnowej.
Interesująca jest także druga pod względem ważności zmienna – liczba wizyt z zakupem produktu z kategorii „A” w ciągu ostatnich 12-mcy. Produkty te są wyjątkowo dobrze oceniane przez klientów i pozytywnie wpływają na ich satysfakcję i retencję.
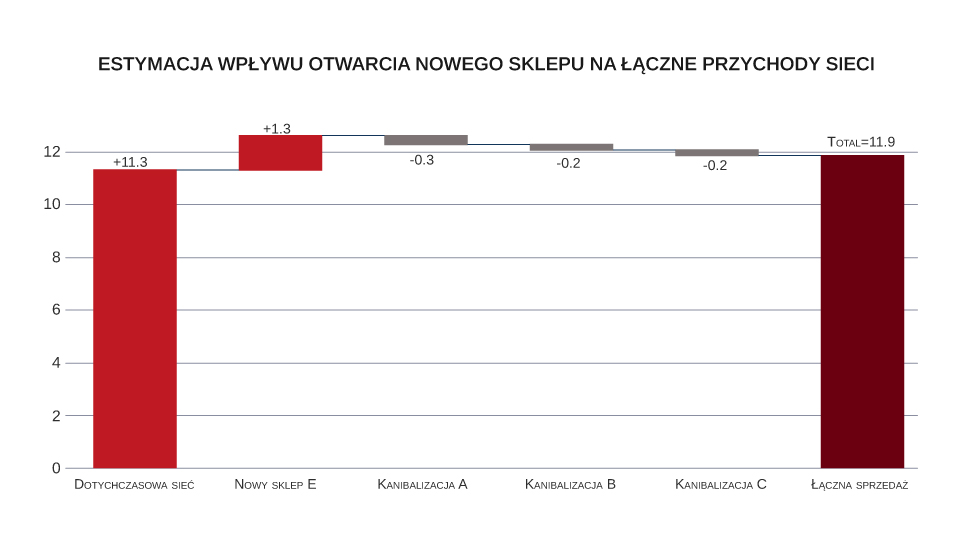
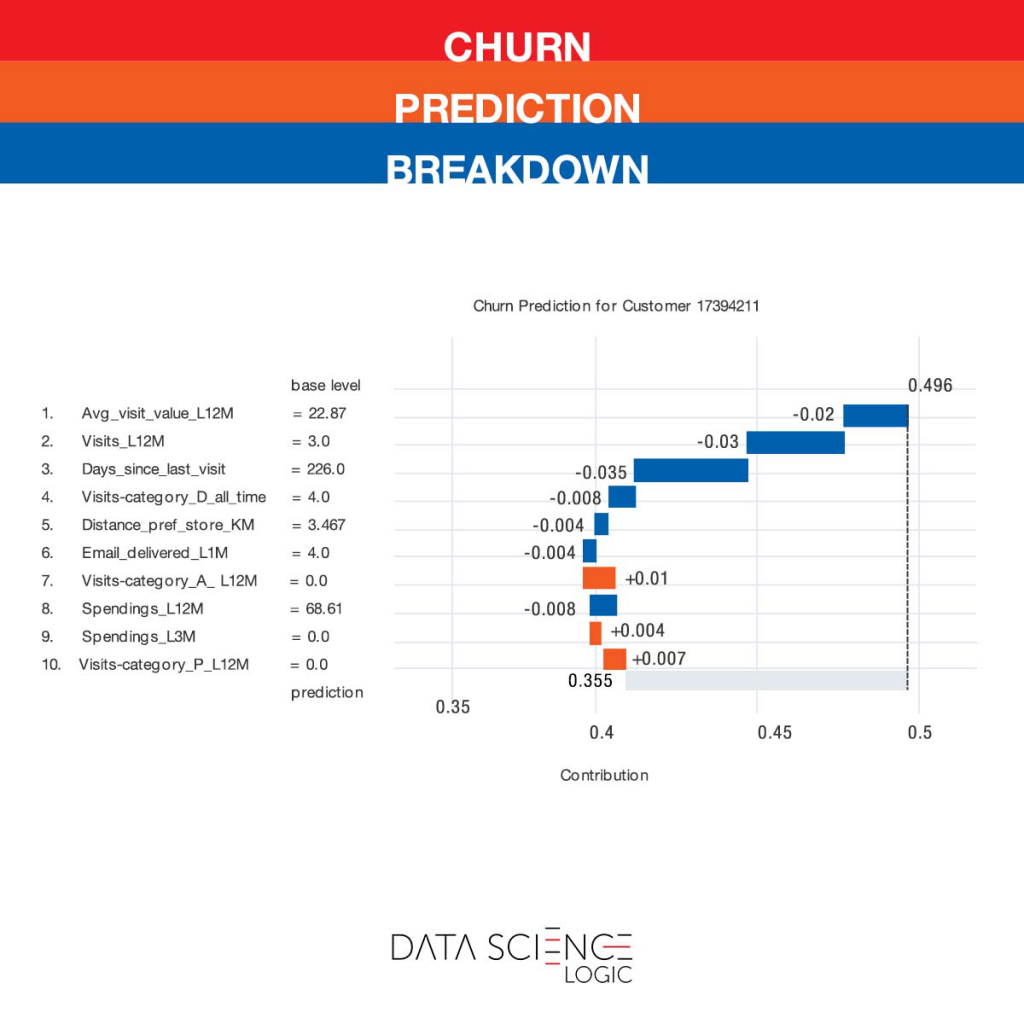
Oprócz ogólnych wniosków na temat czynników wpływających na zagrożenie utratą klientów, model pozwala na predykcję prawdopodobieństwa utraty konkretnej osoby i wskazanie konkretnych cech, które w jej przypadku to ryzyko zwiększają lub zmniejszają, co przedstawia wykres poniżej. W jego przypadku ryzyko jest stosunkowo niskie (35,5% w stosunku do bazowych 49,6%). Ryzyko zmniejszają m.in. średnia wartość wizyty oraz liczba wizyt w ciągu ostatniego roku. Klient nie korzysta natomiast z produktów wspomnianej wcześniej kategorii „A”, co podwyższa ryzyko odejścia. Zachęcenie (np. przez odpowiednia kampanię) do wypróbowanie produktów z tej kategorii prawdopodobnie w jeszcze większym stopniu obniżyłoby ryzyko jego odejścia.
Radzenie sobie z migracją klientów jest jednym z najważniejszych wyzwań stojących obecnie przed firmami, zważając na to jak kosztowne może być później pozyskanie nowego klienta. Dzięki modelowaniu antychurn dowiemy się, którzy klienci mogą odejść i dlaczego, jakie są objawy zwiększającego się ryzyka odejścia, a także w jaki sposób najlepiej zapobiec odejściu.