Baza klientów to istotne aktywo każdego przedsiębiorstwa. Gromadzone o klientach dane pozwalają na lepsze targetowanie komunikacji i przygotowanie bardziej dopasowanej oferty. Zdrowy biznes potrzebuje jednak stałego dopływu nowych klientów. Na ich temat zaś nie ma zazwyczaj danych (lub jest ich niewiele). Gdzie szukać klientów? I czy data science może więc pomóc w docieraniu do nich?
Na postawione powyżej pytanie najlepiej odpowiedzieć na przykładzie. Jakiś czas temu jedna z firm chciała istotnie poszerzyć bazę klientów kupujących jej flagowy produkt. Doświadczenie podpowiadało, że produkt ten jest atrakcyjny dla zupełnie innej grupy konsumentów niż typowy klient firmy. Planowana była akcja reklamowa z wykorzystaniem bilbordów i ulotek. Przy ograniczonym budżecie firma nie chciała jednak „zasypać” materiałami całego miasta i okolic, w których działa. Zamierzała skupić swoje wysiłki i budżet w lokalizacjach o największym prawdopodobieństwie wysokiego zwrotu z inwestycji.
Pierwszym pomysłem, jak wykorzystać dane do rozwiązania tego problemu, było sprawdzenie skąd pochodzą aktualni klienci nabywający produkt. Ich dane adresowe były w bazie dzięki prowadzonemu programowi lojalnościowemu. Przeprowadzono analizę profilu demograficzno-behawioralnego klientów kupujących flagowy artykuł – przedmiot kampanii. W stosunku do typowych klientów, grupa ta cechowała się nadreprezentacją grupy wiekowej 30-35 lat o ponad 10 punktów proc. wyższym udziałem mężczyzn i wyższymi dochodami. Założono, że szczególnie atrakcyjne z punktu widzenia planowanej kampanii będą rejony o ponadprzeciętnym udziale mieszkańców o takiej właśnie charakterystyce. Wytypowano zatem obszary (osiedla, dzielnice, gminy) na podstawie kilku źródeł danych. Pochodziły one m.in. z informacji udostępnianych publicznie przez Główny Urząd Statystyczny oraz oferowanych komercyjnie przez różnych dostawców prywatnych.
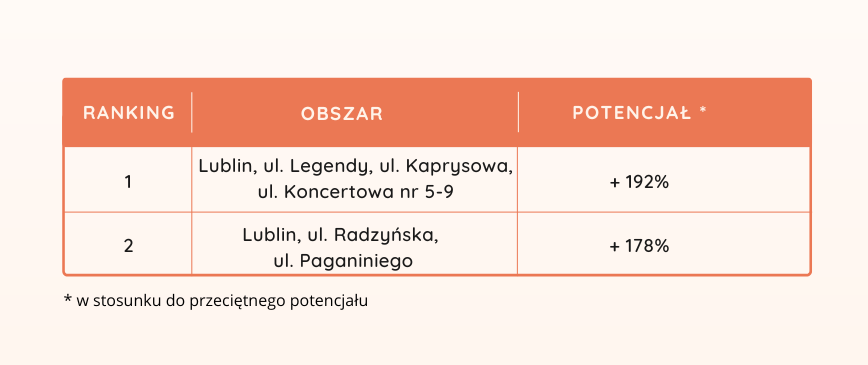
W obawie, że samo wskazanie miejsc zamieszkania klientów o podwyższonym zainteresowaniu nie wystarczy, potrzebne było bardziej precyzyjne oszacowanie potencjału sprzedażowego poszczególnych lokalizacji. Krótko mówiąc, szukano odpowiedzi na pytanie: na jaką sprzedaż możemy liczyć? W tym celu zbudowany został model predykcyjny, który był w stanie dla każdego obszaru wskazać przewidywaną przyszłą sprzedaż w dowolnie zdefiniowanym okresie. Model wykorzystywał m.in. takie zmienne, jak struktura wieku i płci w poszczególnych dystryktach, dochody na gospodarstwo domowe, czas dojazdu do punktu obsługi, zachowania zakupowe istniejących klientów z danej okolicy. Przeciętny błąd predykcji modelu wahał się w granicach +/- 6%. Dla zilustrowania poziomu szczegółowości, z jaką model był w stanie wskazać lokalizacje poniższa tabela zawiera definicję dwóch topowych rekomendacji modelu predykcyjnego.
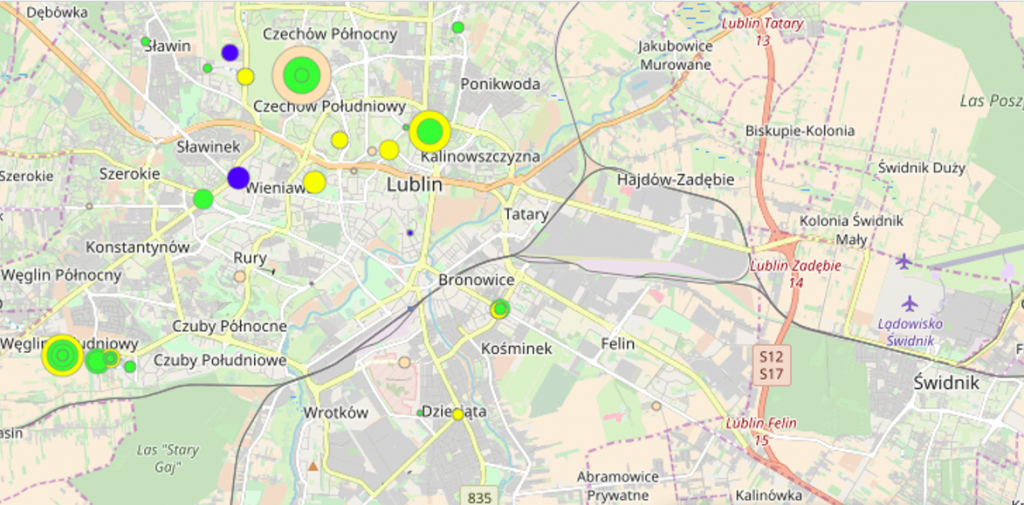
Obszary z największym potencjałem wskazane przez model zostały także zwizualizowane na mapach (przykład jednej z nich poniżej).
W celu dokonania oceny trafności rekomendacji modelu porównane zostały efekty przeprowadzonych działań w grupie 10 najlepszych miejsc wskazanych przez model z 10 lokalizacjami z miejsc 11-20 rankingu. Zwrot z inwestycji w grupie rekomendowanej przez model był o ponad 21% wyższy w stosunku do grupy porównawczej.
Data science w odpowiedni sposób, łącząc wewnętrzne i zewnętrzne źródła danych o różnym poziomie szczegółowości (dane dotyczące indywidualnego klienta z danymi zagregowanymi opisującymi całe obszary), może pomagać rozwiązywać różnorakie problemy, przed jakimi staje biznes. Tym samym przyczynia się do zwiększania zwrotu z inwestycji.