Gdy pod koniec 1971 roku Ray Tomlinson, amerykański inżynier i programista, wysłał pierwszą w historii wiadomość email, nie mógł sobie zdawać sprawy z tego, jakie zastosowania znajdzie jego wynalazek. A już na pewno nie pomyślałby, że ktoś przy pomocy tego typu wiadomości będzie przekonywał innych do kupowania swoich produktów. Jednak, ponad 50 lat od pierwszej wiadomości, email marketing jest jednym z najważniejszych kanałów komunikacji marketingowej. Wyzwaniem pozostaje natomiast utrzymanie skuteczności tego kanału. Mogą w tym pomóc narzędzia AI. Zanim jednak zacznie się je stosować, warto zadać sobie pytanie od czego należy zacząć?
Skuteczny email marketing – jak zacząć?
Wiem, że to co zaraz napiszę, zwłaszcza jeśli ktoś będzie to czytał w oderwaniu od kontekstu, zabrzmi banalnie, ale czasami warto wrócić do fundamentów. A fundamentalną zasadę marketingu emailowego można streścić w taki sposób: jeśli klient nie otworzy maila, nie dowie się co chcieliśmy mu przekazać. A jeśli nie zrobi tego, nie będzie szansy na wykonanie akcji, do której chcielibyśmy go przekonać. Przygodę z email marketingiem należy zatem rozpocząć od skłonienia klienta by nasz mailing w ogóle otworzył. Tymczasem marketerzy wiedzą ze swoich statystyk wskaźnik open rate, że zazwyczaj większość emaili jest ignorowana lub wręcz usuwana bez otwierania. Dlaczego?
W naszych rozważaniach pominiemy wiadomości, które są w sposób oczywisty spamem. Jeśli nie znam adresu nadawcy, nie zapisywałem się by otrzymywać takie emaile lub wyglądają one podejrzanie, najmądrzejszym co mogę zrobić, to je jak najszybciej usunąć. Interesują nas zatem wszystkie pozostałe emaile i odpowiedź na pytanie, dlaczego odbiorcy ich nie czytają. Otóż według raportu firmy SARE wśród głównych przyczyn kasowania maili bez otwiercia odbiorcy wskazują:
- dostaję zbyt wiele wiadomości od jednego nadawcy (31,9% odpowiedzi),
- tytuł nie jest interesujący (33,4%).
Powody te stanowią ponad 65% wszystkich przypadków. Co interesujące i pozytywne z punktu widzenia osób odpowiedzialnych za komunikację marketingową, na oba te czynniki nadawca ma wpływ i jest w stanie lepiej ukierunkować i spersonalizować swoje działania email marketingowe. Zatem można powiedzieć, że wystarczy wysyłać na skrzynki klientów mniej wiadomości i pisać bardziej interesujące tytuły , a zwrot z inwestycji będzie wyższy. Proste, prawda? Niestety wszyscy wiemy, że nie do końca tak jest. Zaryzykowałbym nawet stwierdzeniem, że w wielu przypadkach będzie to zwyczajnie trudne.
Prowadzenie kampanii mailingowych. W jaki sposób poprawić ich skuteczność?
Dla pierwszego powodu, trudność stanowi określenie ile to jest „zbyt wiele”. Czy raz w tygodniu to już zbyt wiele? A może dopiero raz dziennie to zbyt wiele? A może dla jednego użytkownika trzy razy w tygodniu to zbyt wiele, ale dla innego nawet cztery razy w tygodniu jest jeszcze ok? A może… No właśnie. Różnych scenariuszy jest właściwie nieskończenie wiele. Nie sposób wszystkich wymienić, a co dopiero przetestować. Do tego nie powinniśmy przecież zakładać, że zainteresowanie i cierpliwość klienta są niezmienne w czasie. Sposobem na rozwiązanie tego zagmatwanego problemu mogą być jedynie modele AI oparte o uczenie maszynowe. Na podstawie historycznych i ciągle napływających nowych danych są w stanie dokonywać bardzo dokładnej predykcji i optymalizacji odpowiedniej częstotliwości wysyłek dla każdego pojedynczego konsumenta. Ciągle się przy tym doskonalą i dostosowują się do zmian w oczekiwaniach odbiorcy. Są w stanie wychwycić nawet bardzo subtelne sygnały „przegrzania” grup docelowych i zarekomendować zmniejszenie tempa. Ktoś może powiedzieć: ale to wszystko wygląda na skomplikowane i pewnie drogie we w wdrożeniu i utrzymaniu, lepiej bądźmy ostrożni i po prostu rzadziej wysyłajmy emaile. Trudno się z takim stanowiskiem nie zgodzić. Nie jest to jednak strategia optymalna. W przypadku klientów skłonnych otwierać twoje wiadomości częściej i reagować zakupem, tracisz w ten sposób dużą część potencjalnych przychodów. Nie wykorzystujesz zatem potencjału swojej bazy kontaktowej.
Przejdźmy do drugiego problemu, czyli nieinteresującego tytułu. Słyszę już głosy jakie pojawiają się w głowach niektórych z Czytelników. – Zaraz nam będzie coś pisał o testowaniu i AI, a my przecież i bez AI robimy testy, i to dużo.
Z przytaczanego już wcześniej raportu firmy SARE wynika, że około 84% nadawców przeprowadza testy przed wysyłką kampanii. Jednak tylko w przypadku niespełna 17% są testy A/B/X. Jedna z firm, z którymi miałem styczność, przeprowadza przykładowo testy tytułu wiadomości. Przygotowywane są trzy warianty tytułu. Następnie wybierana jest losowo grupa około 15% bazy kontaktów. Grupa ta dzielona jest na trzy równe części, z których każda otrzymuje jeden wariant tytułu. Wariant, który w ramach wysyłki pilotażowej osiągnie najwyższy open-rate jest następnie wysyłany do pozostałych 85% adresatów. Mamy więc testy, mamy segmentację, mamy optymalizację, jest ok. Ciśnie się jednak na usta pytanie: co tak właściwie przetestowaliście i na jakie pytanie uzyskaliście odpowiedź? Czy na pewno wybraliście najlepszy wariant tytułu, czy tylko najlepszy spośród trzech zaproponowanych? Skąd wiecie, że nie ma 20 innych wariantów, z który każdy jest lepszy od zwycięskiego wśród testowanych trzech? Nie wiemy, ale nawet gdybyśmy chcieli sprawdzić więcej tematów wiadomości to uzyskamy mało liczne grupy. Cóż więc zrobić, aby tytuł w email marketingu był skuteczny i przekładał się na wyższe konwersje?
E-mail marketing a AI
Tak, niektórzy z Czytelników na pewno się już domyślają, teraz przyszedł czas na pisanie o AI. Oparty o głębokie uczenie neuronowe model jest w stanie kumulując dane o aktualnie i historycznie wysyłanych wiadomościach, przewidzieć reakcję i oszacować najbardziej prawdopodobny wskaźnik otwarć dowolnego tytułu. Zadziała nawet dla tytułu jakiego nigdy wcześniej nie wysyłaliście. Naprawdę. A jeśli nawet model będzie w takim wypadku nieco mniej pewny swojej predykcji to Was o tym poinformuje. Pamiętać tylko trzeba, że sam tytuł to zbyt mało informacji. W końcu, wracając do fundamentów (albo banałów, jak kto woli), ważne jest nie tylko co mówimy ale do kogo to mówimy, a nawet kiedy to mówimy. Ta sama wiadomość może być zupełnie inaczej zrozumiana: jeden się ucieszy, a drugi obrazi.
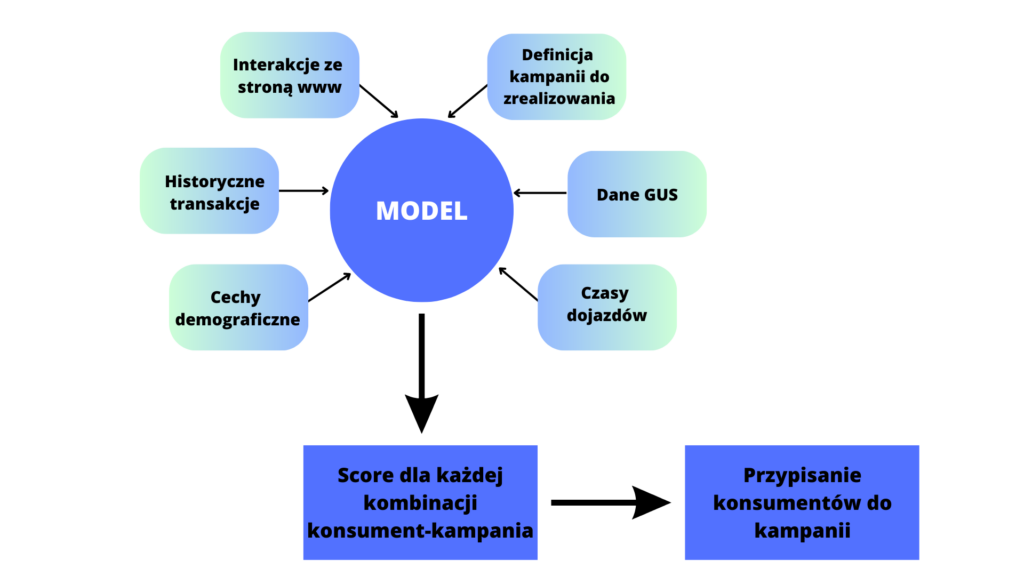
Nie wystarczy więc model AI rozumiejący tytuł wiadomości, ale oderwany od kontekstu. Pozbawiony informacji o grupach odbiorców, cechach klientów, historii relacji firmy z nimi, historii ich zakupów, momentu. Potrzebny jest system integrujący dane o tych zjawiskach i dostarczający modelowi AI odpowiedniego kontekstu. Ogólny schemat można zobaczyć poniżej.
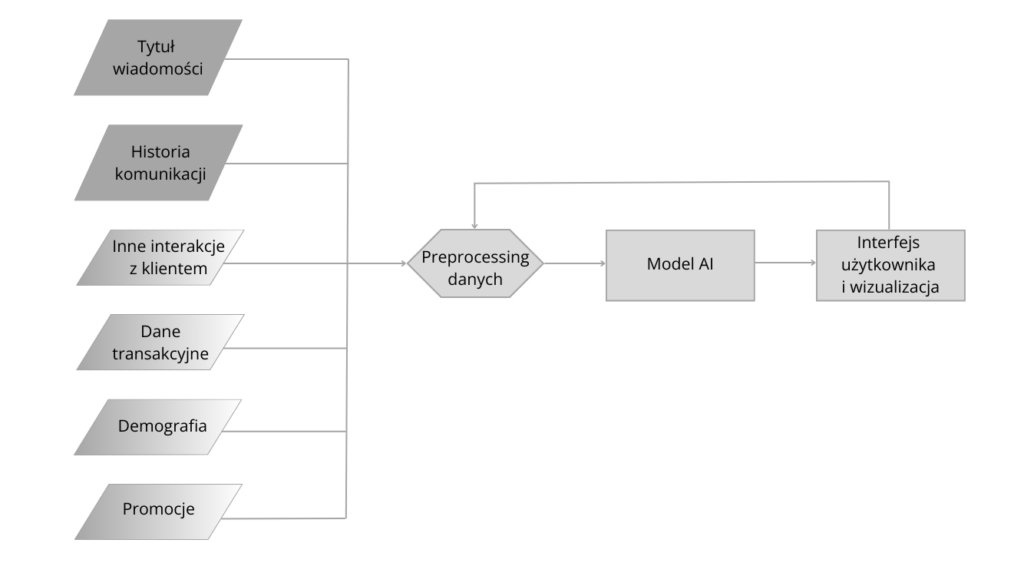
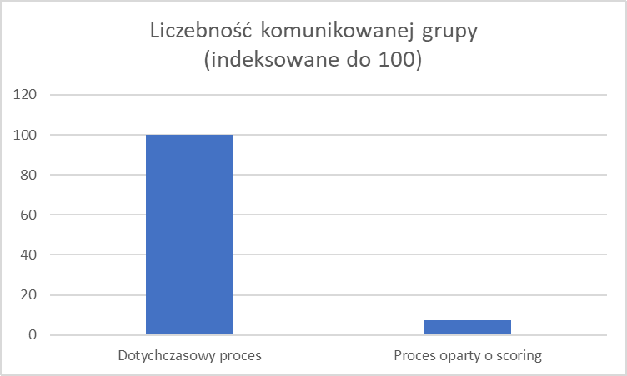
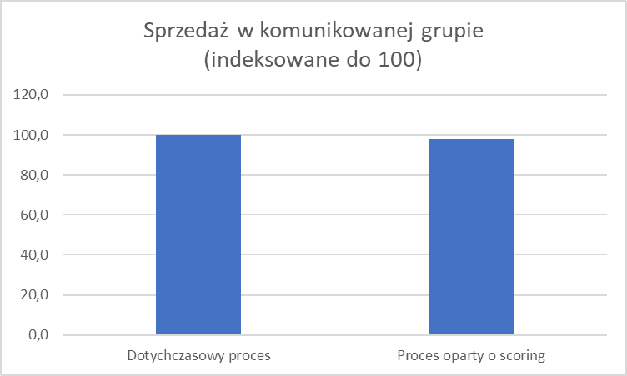
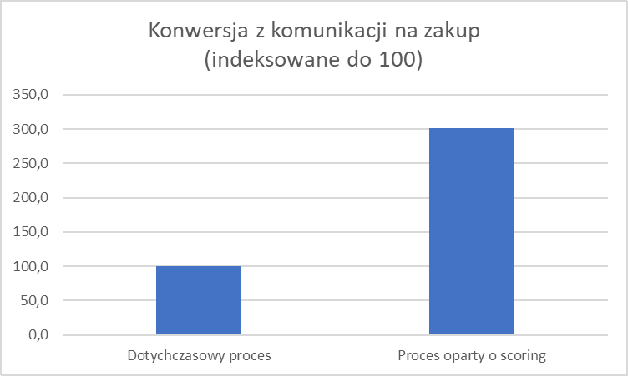
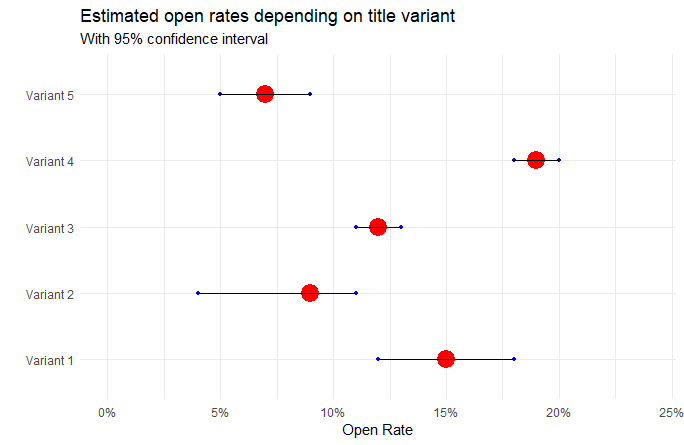
Dzięki poprawnie zdefiniowanemu, wytrenowanemu i skalibrowanemu modelowi możemy testować różne warianty tytułów i uzyskiwać informacje jak na przykładach poniżej. Liczba wariantów może być dowolna, tak samo jak liczba segmentów. I co najlepsze, aby przeprowadzić test i oszacować spodziewaną otwieralność nie musimy wysyłać ani jednego emaila do twoich odbiorców. Wszystko możemy przeprowadzić korzystając z symulacji komputerowej.
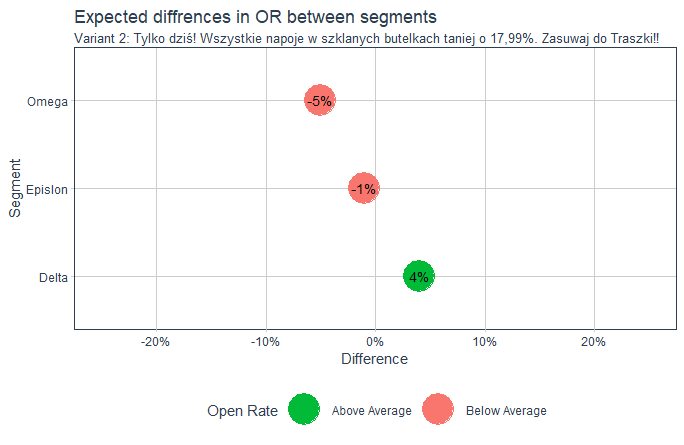
Prowadzenie skutecznego email marketingu – podsumowanie
Ray Tomlinson zapytany wiele lat później jaka była treść pierwszego emaila w historii, odpowiedział, że nie pamięta. Najważniejsze było to, że wiadomość dotarła na adres odbiorcy. Treść nie była ważna. Nie miała żadnego znaczenia. W komunikacji marketingowej jest dokładnie odwrotnie. Samo dotarcie emaila to za mało. Ważna jest treść maila. Ważny jest też interesujący tytuł. Bo bez tego znaczna część adresatów nie odczyta treści.