Baza klientów to istotne aktywo każdego przedsiębiorstwa. Gromadzone o klientach dane pozwalają na lepsze targetowanie komunikacji i przygotowanie bardziej dopasowanej oferty. Zdrowy biznes potrzebuje jednak stałego dopływu nowych klientów. Na ich temat zaś nie ma zazwyczaj danych (lub jest ich niewiele). Gdzie szukać klientów? I czy data science może więc pomóc w docieraniu do nich?
Na postawione powyżej pytanie najlepiej odpowiedzieć na przykładzie. Jakiś czas temu jedna z firm chciała istotnie poszerzyć bazę klientów kupujących jej flagowy produkt. Doświadczenie podpowiadało, że produkt ten jest atrakcyjny dla zupełnie innej grupy konsumentów niż typowy klient firmy. Planowana była akcja reklamowa z wykorzystaniem bilbordów i ulotek. Przy ograniczonym budżecie firma nie chciała jednak „zasypać” materiałami całego miasta i okolic, w których działa. Zamierzała skupić swoje wysiłki i budżet w lokalizacjach o największym prawdopodobieństwie wysokiego zwrotu z inwestycji.
Pierwszym pomysłem, jak wykorzystać dane do rozwiązania tego problemu, było sprawdzenie skąd pochodzą aktualni klienci nabywający produkt. Ich dane adresowe były w bazie dzięki prowadzonemu programowi lojalnościowemu. Przeprowadzono analizę profilu demograficzno-behawioralnego klientów kupujących flagowy artykuł – przedmiot kampanii. W stosunku do typowych klientów, grupa ta cechowała się nadreprezentacją grupy wiekowej 30-35 lat o ponad 10 punktów proc. wyższym udziałem mężczyzn i wyższymi dochodami. Założono, że szczególnie atrakcyjne z punktu widzenia planowanej kampanii będą rejony o ponadprzeciętnym udziale mieszkańców o takiej właśnie charakterystyce. Wytypowano zatem obszary (osiedla, dzielnice, gminy) na podstawie kilku źródeł danych. Pochodziły one m.in. z informacji udostępnianych publicznie przez Główny Urząd Statystyczny oraz oferowanych komercyjnie przez różnych dostawców prywatnych.
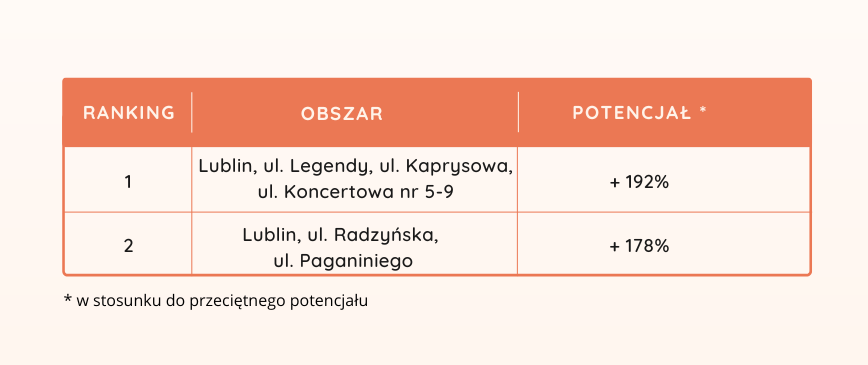
W obawie, że samo wskazanie miejsc zamieszkania klientów o podwyższonym zainteresowaniu nie wystarczy, potrzebne było bardziej precyzyjne oszacowanie potencjału sprzedażowego poszczególnych lokalizacji. Krótko mówiąc, szukano odpowiedzi na pytanie: na jaką sprzedaż możemy liczyć? W tym celu zbudowany został model predykcyjny, który był w stanie dla każdego obszaru wskazać przewidywaną przyszłą sprzedaż w dowolnie zdefiniowanym okresie. Model wykorzystywał m.in. takie zmienne, jak struktura wieku i płci w poszczególnych dystryktach, dochody na gospodarstwo domowe, czas dojazdu do punktu obsługi, zachowania zakupowe istniejących klientów z danej okolicy. Przeciętny błąd predykcji modelu wahał się w granicach +/- 6%. Dla zilustrowania poziomu szczegółowości, z jaką model był w stanie wskazać lokalizacje poniższa tabela zawiera definicję dwóch topowych rekomendacji modelu predykcyjnego.
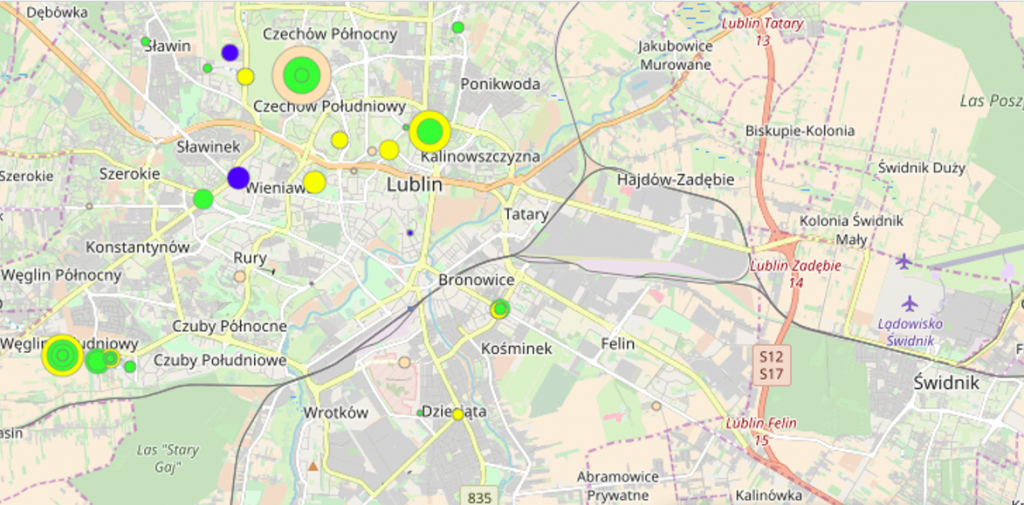
Obszary z największym potencjałem wskazane przez model zostały także zwizualizowane na mapach (przykład jednej z nich poniżej).
W celu dokonania oceny trafności rekomendacji modelu porównane zostały efekty przeprowadzonych działań w grupie 10 najlepszych miejsc wskazanych przez model z 10 lokalizacjami z miejsc 11-20 rankingu. Zwrot z inwestycji w grupie rekomendowanej przez model był o ponad 21% wyższy w stosunku do grupy porównawczej.
Data science w odpowiedni sposób, łącząc wewnętrzne i zewnętrzne źródła danych o różnym poziomie szczegółowości (dane dotyczące indywidualnego klienta z danymi zagregowanymi opisującymi całe obszary), może pomagać rozwiązywać różnorakie problemy, przed jakimi staje biznes. Tym samym przyczynia się do zwiększania zwrotu z inwestycji.
Komunikacja mailowa to wciąż wiodący kanał bezpośredniego kontaktu z konsumentami. Istnieje wiele przykładów firm, które wykorzystując ten kanał, z powodzeniem zwiększają zaangażowanie konsumentów i obroty. Zbyt agresywne prowadzenie kampanii może powodować jednak spadek otwieralności i pozytywnych efektów maili. Zbyt zachowawcze podejście do wykorzystania mailingów może uniemożliwić realizację pełnego potencjału zakupowego bazy konsumentów. Wraz z wzrastającą liczbą sprzedawanych produktów, coraz bardziej wyśrubowanymi oczekiwaniami klientów oraz coraz silniejszą konkurencją, optymalne planowanie kampanii staje się jeszcze większym wyzwaniem. Na szczęście data science może pomóc.
Recepta na sukces jest prosta. Trzeba wysyłać do konsumenta maksymalnie dużo wiadomości email, nie więcej i nie częściej jednak niż jest on w stanie znieść. Trzeba wysyłać do konsumenta wiadomości o potencjalnie najbardziej dochodowych produktach, nie takich jednak, które go zupełnie nie interesują. Wreszcie trzeba wysyłać wiadomości w odpowiednich momentach, zarówno pod względem preferencji konsumenta, jak i kalendarza kampanii i potrzeb „dopalenia” sprzedaży. No i dobrze byłoby nie informować klienta o produktach, które i tak zamierza kupić. Zasady są okrutnie proste. Dlaczego więc ich realizacja w praktyce bywa tak trudna?
Jak optymalizować działania marketingowe – przykład
Poszukując odpowiedzi na to pytanie, posłużymy się następującym bardzo uproszczonym z konieczności przykładem. Firma sprzedaje trzy produkty A, B i C. Każdy z nich będzie przedmiotem kampanii, które realizowane będą w rozważanym 4-tygodniowym okresie.
Produkt A promowany będzie w tygodniu 23, produkt B we wszystkich tygodniach, a produkt C tylko w ostatnim 24 tygodniu. Najbardziej dochodowy dla firmy jest produkt C – każda sztuka to 250 zł marży. Dla produktu A i B jest to zaś odpowiednio 100 i 50 zł. Powyższe informacje podsumowane są w tabeli
Produkt / Tydzień kampanii
21
22
23
24
Zaysk jednostkowy
A
X
100
B
X
X
X
X
50
C
X
250
Załóżmy też, że firma ma tylko 100 klientów i każdy z nich ma inne preferencje co do częstotliwości wysyłek. Przykładowo konsument nr 1 akceptuje częstotliwość nie większą niż raz na 2 tygodnie. Wysyłka do niego może być więc zrealizowana albo w tygodniach 21 i 23 bądź w 22 i 24 tygodniu. Konsument nr 2 jest nieco bardziej przewrażliwiony na punkcie częstotliwości komunikacji i już wysyłki częstsze niż raz na 4 tygodnie jest skłonny uznać za nadmierne spamowanie. Wysyłka do niego może być więc zrealizowana tylko w jednym z 4 tygodni itd.
Załóżmy wreszcie, że naszym celem jest maksymalizacja efektu dla całego czterotygodniowego okresu. Przez efekt zaś rozumiemy łączną wygenerowaną dzięki kampanii dodatkową sprzedaż. Zakładamy także, że w jednym tygodniu nie można wysłać do danego odbiorcy więcej niż jednej wiadomości. W tygodniach więc, w których prowadzone są więcej niż jedna kampania musimy wybrać, którą wyślemy. Nie wysyłamy też więcej niż jednej wiadomości dotyczącej danej kampanii do tego samego klienta.
Nawet przy tak skromnej bazie: 3 produkty, 4 tygodnie, 100 konsumentów mamy do podjęcia 24 x 3 x 100, czyli 4800 zerojedynkowych decyzji czy wysyłać danemu klientowi daną kampanię w danym tygodniu czy nie. Wystarczy, że dołożymy tylko jeszcze jeden produkt i rozszerzymy okres do 5 tygodni a liczba decyzji rośnie do 12800. Gdybyśmy chcieli optymalizować kalendarz dla kwartału (12 tygodni) przy tej samej liczbie produktów i klientów dochodzimy już do 1638400 kombinacji. A przecież mało która firma ma tylko 100 klientów i sprzedaje 4 produkty…
Widzimy więc, że liczba decyzji, które trzeba podjąć rośnie bardzo dynamicznie. Nawet dla tak małej bazy nie sposób podjąć tylu decyzji ręcznie.
Co więc w takiej sytuacji robimy?
Możemy zrezygnować z optymalizacji i wysyłać każdemu wszystko zawsze albo wybierać losowo.
Możemy przyjąć metodę przybliżoną, która nie gwarantuje znalezienia optymalnego rozwiązania, ale daje szansę na znalezienie rozwiązania lepszego niż losowe. Przykładowo dla każdego konsumenta przypisujmy kolejno najbardziej dochodowe kampanie. Ten intuicyjny sposób nie gwarantuje wcale jednak osiągnięcia maksymalnego globalnego efektu. Być może, biorąc pod uwagę wszystkie ograniczenia jakie mamy, dla danego konsumenta lepiej byłoby zrezygnować z wysyłki najbardziej dochodowej kampanii i dzięki temu mieć możliwość wysłania mu dwóch nieco mniej dochodowych, które jednak w sumie przyniosą wyższy zysk.
ponad 30-procentowy wzrost wskaźnika open rate (dzięki optymalnej częstotliwości),
ponad 6-procentowy wzrost wartości sprzedaży w grupie targetowanej w optymalny sposób w stosunku do grupy targetowanej przy pomocy uproszczonych metod decyzyjnych,
blisko 50-procentowa oszczędność czasu i zasobów ludzkich przy planowaniu kampanii.
Podsumowanie
Na koniec warto wspomnieć, że w świecie, w którym oprócz mailingów wysyłamy także smsy oraz kontaktujemy się z klientami innymi kanałami liczba możliwych kombinacji decyzji jest jeszcze większa. Tym większe będą zatem korzyści z optymalizacji matematycznej. Unikniemy też sytuacji, w której z trudem ułożony ręcznie plan (a i tak nie optymalny) posypie się gdy trzeba będzie „tylko o tydzień” przesunąć jedną kampanię, a ze względu na problemy z dostawami pewnego produktu wolumen wiadomości z nim związanych trzeba będzie ograniczyć o 50%. Ludzki planista nie zdoła zmodyfikować w terminie planu, lub z dnia na dzień odejdzie z pracy. Odpowiednio napisany program optymalizacji matematycznej poradzi sobie z tym zadaniem w przeciągu minut lub godzin. Pozwoli przy tym osiągnąć maksymalny możliwy w danych warunkach i przy danych ograniczeniach zysk z kampanii.
Współczesny konsument jest wciąż bombardowany komunikatami. Konkurencja o coraz krótsze okresy uwagi jest krwawa i liczy się w niej wykorzystanie każdej możliwej przewagi. W jaki sposób data science może pomóc w skutecznej walce o dotarcie z przekazem marki do konsumentów? Poznaj szczegóły wykorzystania uczenia maszynowego w komunikacji marketingowej.
Jak komunikacja marketingowa wyglądała kiedyś?
W pierwszych latach komercyjnego internetu, kiedy dopiero rozpoczynało się wykorzystywanie e-maili w komunikacji marketingowej, zadanie było w miarę proste. Nie było jeszcze dużej konkurencji , działał efekt świeżości, konsumenci byli bardziej skłonni otwierać i czytać wiadomości. Można powiedzieć, że do sukcesu wystarczało samo posiadanie bazy adresowej i realizowanie jakichkolwiek wysyłek. Wystarczające było stosowanie prostego modelu nieco żartobliwie określanego jako „Wszystko Każdemu Zawsze” (WKZ). Nazwa odzwierciedla tendencję do wysyłania każdej przygotowanej komunikacji do całej dostępnej bazy adresatów. Strategia ta opierała się na założeniu, że każda wysłana wiadomość w jakimś stopniu zwiększa prawdopodobieństwo pozytywnej reakcji, a koszt wysłania każdej dodatkowej wiadomości jest bliski zeru. W przypadku smsów koszt mógł być oczywiście czynnikiem ograniczającym wolumen wysyłanych wiadomości. W bardzo wielu sytuacjach radzono sobie z tym jednak w prosty sposób, proporcjonalnie zmniejszając wolumen tak, żeby wyczerpać, ale nie przekroczyć przyznanego budżetu.
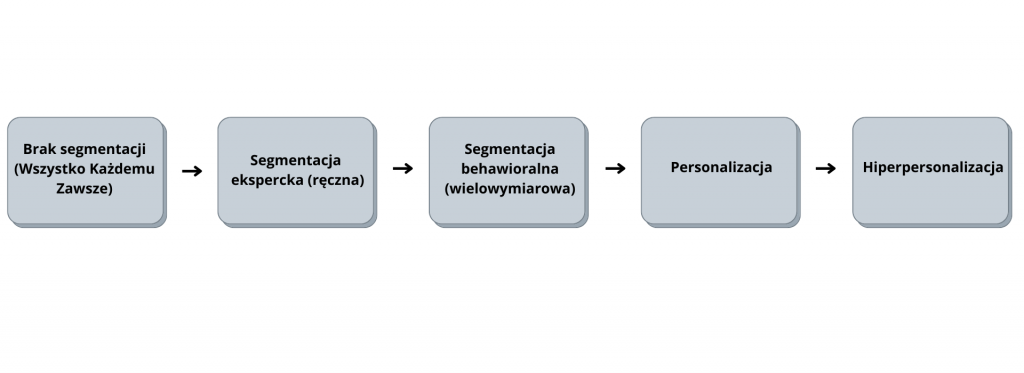
Od braku segmentacji do hiperpersonalizacji
Sytuacja zaczęła zmieniać się wraz ze wzrostem liczby marek wykorzystujących kanały email i sms w komunikacji. Skrzynki odbiorcze konsumentów zaczęły „pękać w szwach”. Liczby otrzymywanych wiadomości przekraczały możliwości percepcji. Komunikacja marketingowa w wielu przypadkach zaczęła być postrzegana jako niechciana („spam”). Przyczyniło się do tego także powszechne stosowanie wspominanego wcześniej modelu WKZ. Rolę odgrywały przede wszystkim brak dostosowania treści do specyfiki konsumenta oraz zbyt częste wysyłki. Pozornie zerowy koszt wysyłki („najwyżej klient nie otworzy”) nie zachęcał do inwestowania czasu i środków w precyzję targetowania. W kalkulacjach nie brano jednak pod uwagę, że reakcją konsumenta na nadmiar komunikatów będzie stopniowe uodparnianie się na przekaz i spadające zainteresowanie otwieraniem wiadomości.
Pierwszym krokiem na drodze wyjścia z sytuacji było przyznanie, że konsumenci w bazie nie są jednakowi. Mają różne potrzeby i cechy. W związku z tym wysyłana do nich treść powinna być odpowiednio dostosowana. Rozpoczęto segmentować bazę. Dominowała segmentacja ręczna w oparciu o wiedzę ekspercką i zdefiniowane z góry segmenty. W tym podejściu liczba możliwych do zastosowania cech konsumenta i segmentów była ograniczona ludzkimi możliwościami.
Zwiększająca się liczba danych
W raz ze zwiększaniem się wolumenu i zakresu danych na temat konsumenta, jakie gromadzone były w bazach, otwierały się nowe możliwości. Nowe dane w połączeniu z rosnącą mocą obliczeniową i zaawansowaniem algorytmów uczenia maszynowego pozwoliły na zwiększenie liczby wykorzystywanych w segmentacji cech. Segmentacja przybrała charakter behawioralny. Dzięki dużej liczbie analizowanych wymiarów, mogła uwzględnić bardziej złożone aspekty zachowania konsumenta i jego relacji z marką. Zastosowanie uczenia maszynowego pozwoliło też na wyróżnienie i przeanalizowanie większej liczby segmentów. To z kolei przekładało się na większą spójność wyłanianych grup i pozwalało na lepsze dopasowanie komunikacji do odbiorcy.
Kolejnym etapem w opisywanej ewolucji było wykorzystanie modeli predykcyjnych do bardziej spersonalizowanego dopasowania komunikacji na poziomie indywidualnego konsumenta. Wcześniej segmentacja pozwalała na operowanie na poziomie grup konsumentów. Różne segmenty mogły otrzymywać inny komunikat w innym momencie, ale wszyscy odbiorcy należący do danego segmentu otrzymywali to samo. Wraz ze wzrostem poziomu zaawansowania segmentacji liczba segmentów mogła być większa, a konsumenci przypisani do nich z większą dokładnością. Poziom generalizacji był jednak wciąż wysoki i pole do poprawy precyzji działań nadal duże. Zastosowanie predykcyjnych modeli scoringowych stanowiło istotny krok na przód. Model przewidywał prawdopodobieństwo zainteresowania każdego indywidualnego konsumenta przedmiotem danej komunikacji. Mógł to być na przykład konkretny produkt, grupa produktowa, oferta promocyjna.
Uczenie maszynowe
Na podstawie danych o zachowaniach konsumentów zgromadzonych w bazie, algorytm uczył się wzorców. W oparciu o nie, był w stanie przewidzieć, który z palety dostępnych komunikatów w największym stopniu pozytywnie wpłynie na konkretnego klienta. Dzięki temu każdy odbiorca w bazie, bez względu na przypisany do niego segment, mógł otrzymać najbardziej odpowiednią treść. Jeśli dla żadnego z zaplanowanych wariantów model nie prognozował wystarczająco wysokiego zainteresowania konsumenta, mógł on zostać wyłączony z danej wysyłki. Pozwalało to na dużą skalę wprowadzić w życie zasadę, że jeśli nie mamy dla ciebie w tym momencie niczego ciekawego do powiedzenia, to lepiej pomilczmy. Dzięki temu konsument mógł mieć poczucie, że dostaje tylko wiadomości dla niego istotne. Nie brakuje przykładów projektów, w których wdrożone zostały tego typu modele predykcyjne. Dzięki temu percepcja odbiorców zmieniła się z „przestańcie wysyłać mi ten spam” na „kiedy dostanę kolejny newsletter”.
Wykorzystanie uczenia maszynowego w komunikacji marketingowej
Opisane modele scoringowe, w połączeniu z zespołem dodatkowych, jeszcze bardziej zaawansowanych modeli pozwalają posunąć personalizację o kolejny krok ku tak zwanej hiperpersonalizacji. Cechuje się ona między innymi:
– precyzyjnym dostosowaniem momentu wysyłki. Każdy konsument może mieć przypisany idealny moment (w rozumieniu godziny, dnia tygodnia, czasu od poprzedniej wysyłki, czasu od poprzedniej wizyty na stronie etc.).
– Doborem najlepszego kanału komunikacji w powiązaniu z idealnym momentem wysyłki.
– Doborem najlepszej kombinacji zastosowanych kanałów (konsument może przykładowo najlepiej reagować na połączenie emaila i wysłanego dwa dni później smsa).
– Możliwością indywidualizacji elementów kontentu (np. dobranie odpowiednich słów w temacie, wybór najlepszego zdjęcia i innych elementów graficznych.
– Dynamicznym dopasowaniem komunikatu do kontekstu konsumenta w czasie rzeczywistym. Inny komunikat i kanał będzie adekwatny, kiedy konsument zostanie zlokalizowany w galerii handlowej, a inny, kiedy w autobusie w drodze do pracy.
1) warte podkreślenia jest, że wszystkie wymienione wyżej personalizacje odbywają się na podstawie wzorców zachowań, których modele „nauczyły się”, obserwując konsumentów a nie na deklaracjach konsumentów. Klient może deklarować, że chciałby otrzymywać mailingi w dni robocze rano. W rzeczywistości największą skuteczność mają mailingi wysłane do niego w soboty wieczorem.
2) Maksymalna moc opisywanego rozwiązania bierze się z synergii poszczególnych submodeli systemu. Optymalny moment dla danego konsumenta będzie różny dla różnych kanałów. Optymalna sekwencja i kombinacja kanałów może być zależna od charakteru komunikowanej promocji. Wreszcie optymalny tekst komunikatu może zależeć od kanału i lokalizacji użytkownika.
Konkurencja o uwagę konsumentów będzie rosnąć wraz z pojawianiem się kolejnych kanałów kontaktu, a także zwiększa się wraz ze wzrostem świadomości marketerów, co do narzędzi, jakie mogą być w ich dyspozycji. Warto zadać sobie pytanie, na jakim etapie opisywanej ewolucji jest nasza organizacja i co możemy zrobić, żeby wykonać kolejny krok, by zyskać dodatkową przewagę i nie pozwolić prześcignąć się konkurencji.
Wiele firm z sukcesem wdrożyło już w działach marketingowych inteligentne rozwiązania, wykorzystujące dane i ich zaawansowaną analitykę. Zastosowanie rozwiązań data science zwiększa efektywność działań, redukuje koszty, optymalizuje budżety i poprawia ROI. Chcąc pozostać konkurencyjnymi, pozostałe firmy muszą jak najszybciej nadrabiać dystans do liderów. Od czego zacząć? W jaki sposób efektywnie wykorzystać dane dostępne w organizacji? Poznaj sprawdzone podejście ekspertów Data Science Logic.
Segmentacja klientów
Tradycyjne podejście do segmentacji jest ograniczone, co do liczby zmiennych, jakie można wziąć pod uwagę. Na przykład typowy RFM (od ang. recency, frequency, monetary value) bierze pod uwagę tylko trzy zmienne. Metody uczenia maszynowego mogą dokonać segmentacji konsumentów w oparciu o praktycznie nieograniczoną liczbę wymiarów. Uwzględniają nie tylko dane demograficzne, ale także dane behawioralne związane zarówno z zachowaniami zakupowymi, jak i interakcjami konsumenta w różnych punktach styku (np. www, mailingi, aplikacja). W wyniku segmentacji powstają „persony” – typowi reprezentanci segmentu, których charakterystyki pozwalają na zróżnicowanie podejścia i zaplanowanie dla nich optymalnych działań.
Predykcja wartości klienta
Modele uczenia maszynowego mogą z dużą dokładnością przewidywać wartość klienta w całym jego cyklu życia. Jest to możliwe już od momentu pojawienia się pierwszych (nawet szczątkowych) danych na temat relacji konsumenta z firmą. Oczywiście im więcej danych tym dokładniejsza predykcja. Już jednak wstępna predykcja pozwala na podjęcie decyzji, ile opłaca się inwestować w relację z danym klientem. Można dzięki temu skupić uwagę i budżet na najbardziej opłacalnych klientach.
Działania anty-churnowe
Uczenie maszynowe pozwala na precyzyjne wskazanie klientów zagrożonych odejściem. Pozwala to na identyfikację i priorytytetyzację klientów, wobec których trzeba podjąć działania. W połączeniu z modelami predykcyjnymi wartości klienta możliwe jest podjęcie optymalnej decyzji, ile warto zainwestować w utrzymanie danego klienta (np. w postaci rabatu). Przy wykorzystaniu modeli komunikacji bezpośredniej można znaleźć optymalny moment, kanał i treść komunikatu antychurnowego. Model może też wskazać wystarczająco dobrą dla danego klienta ofertę. Przykładowo, jeśli klient zdecydowałby się zostać po otrzymaniu rabatu 5%, to nie ma potrzeby oferowania mu rabatu 15%. Model predykcyjny może więc przyczynić się do istotnych oszczędności budżetu.
Planowanie komunikacji bezpośredniej
Modelowanie predykcyjne w istotny sposób wspiera proces przygotowywania i planowania komunikacji marketingowej – nie tylko antychurnowej. Na podstawie danych o interakcjach konsumentów z firmą, możliwa jest predykcja pozytywnej reakcji danego klienta na określony kontent, ofertę, moment i kanał wysyłki. Pozwala to na optymalizację budżetu – np. wybór tańszego kanału, jeśli spodziewany efekt będzie zbliżony, czy poprawę doświadczenia konsumenta – mniej spamu, bardziej dopasowana treść, najbardziej dogodny kanał komunikacji.
Analiza i rekomendacje kontentu
Zaawansowane modele predykcyjne oparte o tzw. uczenie maszynowe głębokie (ang. deep learning) są w stanie przetwarzać nie tylko dane liczbowe, ale także obraz, tekst, dźwięk czy wideo. Pozwala to na przewidywanie efektu, jaki wywoła u konkretnego klienta kontent wysyłany w komunikacji. Dzięki temu można dobrać odpowiednią treść i tytuł maila, optymalny layout oraz grafikę.
Analiza inkrementalnego efektu promocji
Promocje i obniżki cen stanowią istotną pozycję budżetu. Nic więc dziwnego, że pojawiają się pytania o ich efektywność i wpływ na sprzedaż. Prosta analiza często nie jest wystarczająca. Obniżenie ceny produktu prawie zawsze podwyższa jego sprzedaż. Obserwując tylko dynamikę sprzedaży w okresie promocji, można dojść do wniosku, że zadziałała ona korzystnie. Tymczasem trzeba znaleźć odpowiedź na pytanie, ile wyniosłaby sprzedaż, gdyby nie było tej promocji. Dopiero porównanie tych dwóch wartości (rzeczywistej sprzedaży i hipotetycznej sprzedaży bez promocji) pozwala na ocenę efektu promocji. Zaawansowane modele data science są w stanie z dużą dokładnością estymować bazową sprzedaż, biorąc pod uwagę także takie czynniki jak sezonowość, kanibalizacja, zmienność pogody, efekty kalendarzowe.
Przedstawione przykłady to tylko niektóre z problemów, jakie już dziś rozwiązywane są przy pomocy data science, a wykorzystanie pełnego potencjału danych może znacząco wpłynąć na pozycję firmy na rynku.