Tradycyjne podejście do pomiaru satysfakcji klienta oparte o badania ankietowe przestaje być wystarczające. Korzystając z bogactwa dostępnych danych, przedsiębiorstwa już dziś przełamują ograniczenia dostępnych metod. Predykcja satysfakcji klienta oparta o dane i proaktywne działania podejmowane na jej podstawie to przyszłość tego obszaru.
Satysfakcja klientów jest kluczowa dla utrzymania ich lojalności i stanowi fundament rozwoju biznesu na konkurencyjnym rynku. Nic więc dziwnego, że już od dawna temat ten jest przedmiotem zainteresowania specjalistów z zakresu marketingu. Owocami tego zainteresowania jest wiele opisywanych w literaturze i stosowanych w praktyce metodyk mierzenia satysfakcji klienta. Wśród najpopularniejszych wymienić można m.in. Customer Satisfaction Score, Customer Effort Score czy Net Promoter Score (NPS). Cechą wspólną najpopularniejszych podejść jest ich oparcie o ankiety, w których konsumentowi zadawane są odpowiednio przygotowane pytania (bądź nawet tylko jedno pytanie). Należy podkreślić, że pomiar i analiza satysfakcji klientów przy pomocy wspominanych badań w wielu przypadkach okazywały się skuteczne. Były i są one istotnym elementem sukcesu rynkowego wielu przedsiębiorstw. Metody te nie są jednak pozbawione wad. Według badania przeprowadzonego przez McKinsey&Company wśród najczęściej wymienianych przez specjalistów z obszaru CS/CX pojawiają się:
- ograniczony zasięg
- opóźnienie informacji
- niejednoznaczność odpowiedzi utrudniająca podejmowanie na ich podstawie działań
Ograniczony zasięg
Według przytaczanego wcześniej badania typowa ankiety satysfakcji zbierają odpowiedzi od nie więcej niż 7% klientów firmy. Przyczyny tego są wielorakie. Wśród nich wymienić można ograniczenia budżetowe (koszt badania), brak dostępnego kanału komunikacji z klientem lub brak zgody na komunikację, niskie zainteresowanie klientów udzielaniem odpowiedzi na pytania. Co istotne, skłonność do odpowiedzi na ankietę może być różna w zależności od pewnych cech czy doświadczenia klienta (np. niezadowoleni mogą odpowiadać chętniej). Stawia to pod dużym znakiem zapytania reprezentatywność otrzymywanych wyników i możliwość ich generalizacji na całą bazę konsumentów firmy.
Opóźnienie informacji
Ankiety ze swojej natury są opóźnione w stosunku do zjawiska, które badają. Uniemożliwia to podejmowanie działań wyprzedzających. Działania wobec niezadowolonego klienta możemy podjąć dopiero po tym jak wypełni on ankietę. Praktycy z obszaru satysfakcji klienta często podkreślają jak dużą rolę odgrywa czas reakcji na problematyczne doświadczenia. Doskonały system pomiaru satysfakcji powinien działać w czasie zbliżonym do rzeczywistego. Dzięki temu możliwe będzie podjęcie natychmiastowych działań dla rozwiązania problemu klienta czy zatarcia złego wrażenia, jakie powstało w jego świadomości. Idealnie byłoby przewidywać narastające niezadowolenie klienta zanim ujawni się ono w postaci negatywnej oceny w ankiecie bądź pełnym nerwów kontaktem z obsługą klienta. Takiej możliwości nie ma w systemach pomiaru opartych wyłącznie o ankiety.
Dodatkowe opóźnienia w zbieraniu informacji wynikają z ograniczonej częstotliwości, z jaką można zadawać konsumentowi pytania. Zazwyczaj ankiety przeprowadza się po zakończeniu pewnego etapu podróży konsumenta np. po transakcji. Często nie ma możliwości zadawania pytań we wcześniejszych krokach, na których także mogą pojawić się problemy wpływające negatywnie na doświadczenie klienta. W skrajnym przypadku negatywne doświadczenie np. przy składaniu zamówienia może zakończyć się tym, że do transakcji w ogóle nie dojdzie. Jeśli ankietujemy tylko po transakcji, to w takiej sytuacji nie uzyskamy żadnej informacji, gdyż konsument nie spełni kryterium (transakcja) do otrzymania ankiety.
Oczywiście zdarzają się firmy, w których procesy ankietowe nie są poddane takim ograniczeniom. Firmy te ankiety przeprowadzają po każdym etapie podróży klienta i za każdym razem, kiedy klient wchodzi w interakcję z firmą. Należy jednak pamiętać, że ankieta może być postrzegana przez klienta jako narzędzie inwazyjne. Już sama nadmierna liczba ankiet może więc wpływać negatywnie na jego doświadczenie. Stąd konieczne jest zachowanie rozsądnego balansu pomiędzy częstotliwością ankietowania a chęcią odpowiadania konsumentów. Najlepiej zaś pomyśleć o nieco innym rozwiązaniu, które przedstawimy w dalszej części artykułu.
Niejednoznaczność odpowiedzi utrudniająca podejmowanie
na ich podstawie działań
To ograniczenie jest pochodną dążenia do utrzymania balansu między potrzebami informacyjnymi firmy, a zadowoleniem konsumenta. Wynika zarówno z pokrycia ankietami poszczególnych kroków w consumer journey (opisane wyżej), jak i ograniczeń w długości ankiety. Ankiety krótkie (obejmujące jedno lub kilka pytań) są mało uciążliwe dla konsumenta i mogą też przyczyniać się do lepszego responsu. Sprowadzenie jednak ankiety do jednego pytania może utrudniać zrozumienie, jakie właściwie czynniki wpłynęły na taką a nie inną ocenę konsumenta. Jeśli nie wiemy, co w przypadku tego konsumenta spowodowało negatywną ocenę, trudno jest podjąć na podstawie wyniku jakieś działania mające za zadanie złe wrażenie naprawić.
Podobnie działa ograniczenie liczby momentów, w których zadawane są pytania. Wystawiona przez konsumenta ocena (przykładowo „siedem”) po zakończeniu transakcji jest trudna do przypisania do poszczególnych etapów jego ścieżki. Ustalenie, które etapy spowodowały odjęcie przez konsumenta punktów od maksymalnej noty wymagałoby zadania serii pytań pogłębiających. To wydłuża czas potrzebny na wypełnienie ankiety i zmniejsza szansę na uzyskanie odpowiedzi. Z drugiej strony częstsze ankietowanie (np. po każdy kroku konsumenta) rodzi również opisane wyżej problemy.
Modelowanie predykcyjne jako rozwiązanie
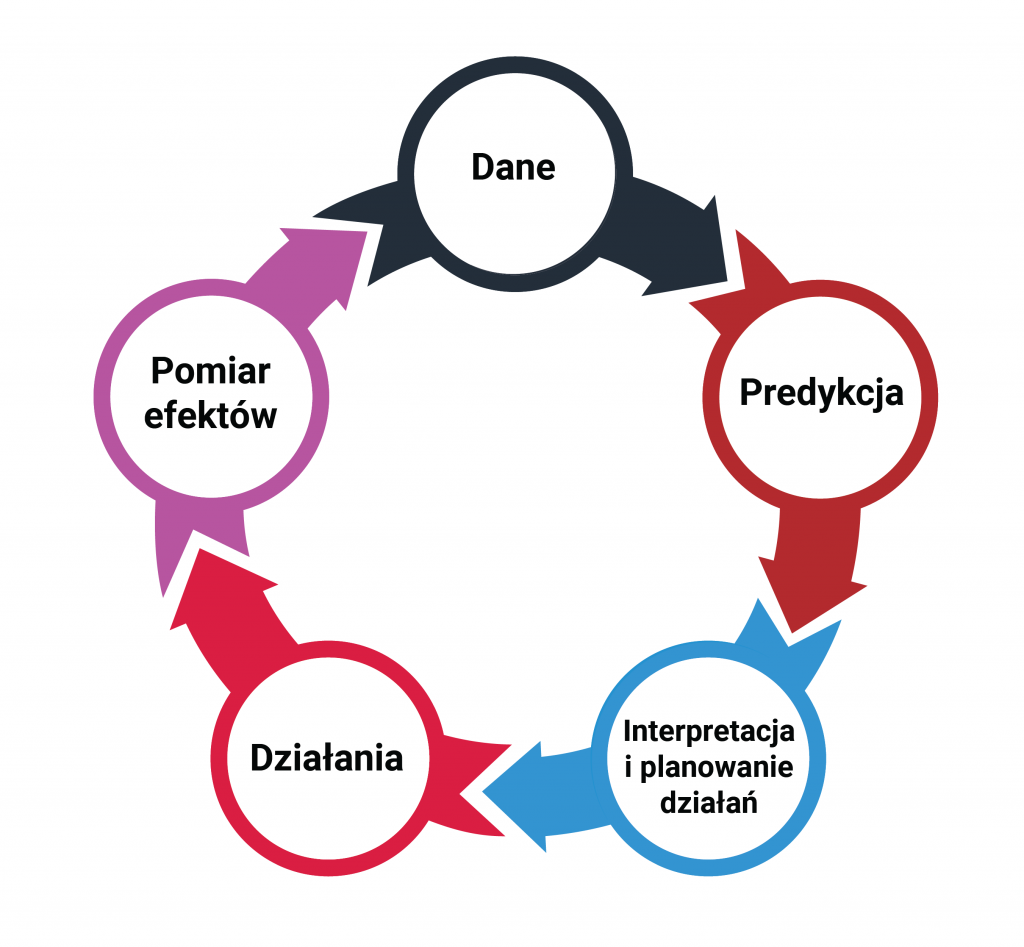
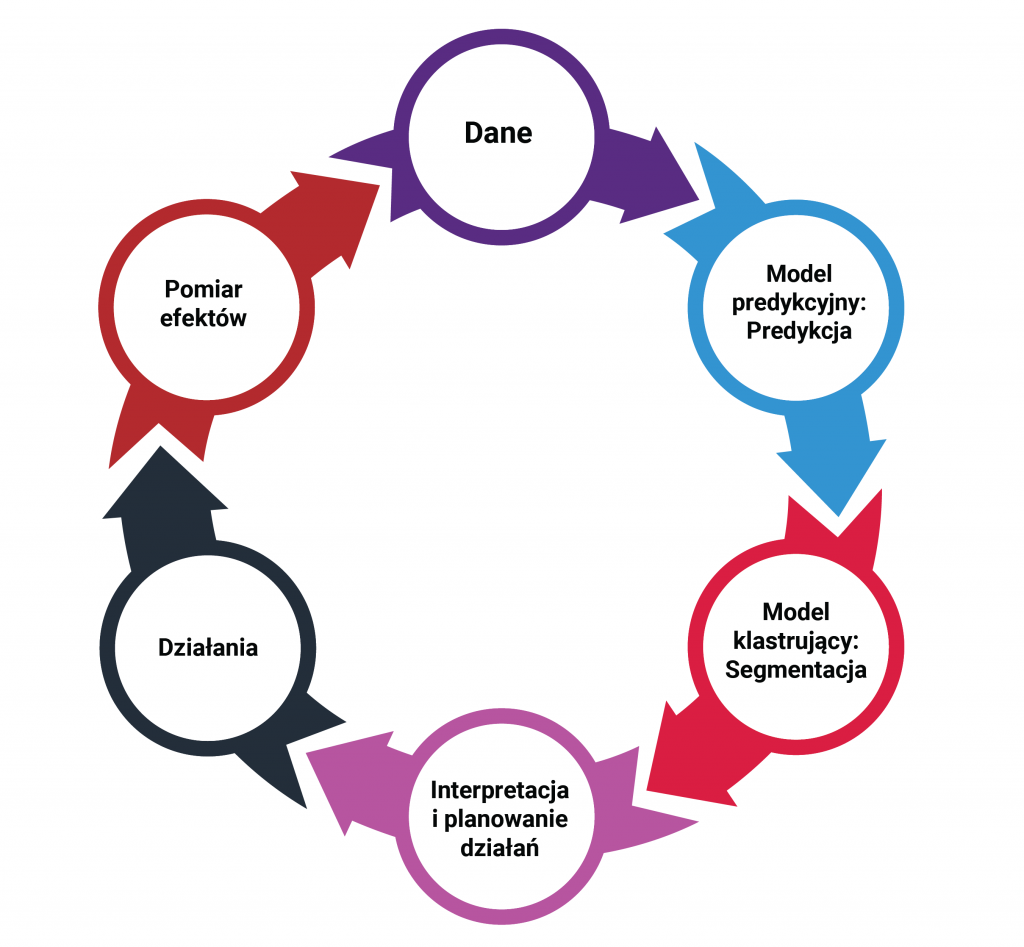
Wykorzystując uczenie maszynowe, możliwe jest zbudowanie modeli zdolnych do przewidywania satysfakcji konsumenta na dowolnym etapie jego podróży do finalizacji transakcji. Wymaga to oczywiście zintegrowania danych z wielu różnych źródeł zazwyczaj obecnych w przedsiębiorstwie. Wymienić tutaj można dane sprzedażowe, z programu lojalnościowego, z biura obsługi klienta, infolinii, strony internetowej, dane finansowe, czy wreszcie dane z dotychczas prowadzonych badań satysfakcji. Dane te są potrzebne na poziomie indywidualnego konsumenta. Wymaga to również posiadania specjalistycznej wiedzy z zakresu data science – potrzeba zespołu zdolnego do budowy i implementacji modeli predykcyjnych. Warto podkreślić, że w rozwiązaniu takim nie rezygnujemy całkowicie z badań ankietowych. Zmieniają one jednak swój charakter. Stają się narzędziem typowo badawczym. Przestają zaś być narzędziem do bieżącego pomiaru satysfakcji.
System działa w ten sposób, że na podstawie danych gromadzonych na bieżąco na temat konsumenta, przewiduje jego aktualny w danym momencie współczynnik satysfakcji. Co więcej wskazuje również jakie czynniki dodatnio a jakie ujemnie na ten wynik wpływają. Pozwala to po pierwsze zidentyfikować klientów, wobec których konieczne jest podjęcie działań, a po drugie zarekomendować konkretne działania, jakie wobec nich trzeba podjąć. Całość pozwala na stałe w czasie zbliżonym do rzeczywistego przewidywanie satysfakcji klientów i podejmowanie skutecznych działań.
Predykcyjne podejście do satysfakcji klienta to z całą pewnością przyszłość. Firmy, które jako pierwsze na swoim rynku wdrożą tego typu rozwiązania wygrają walkę o klienta. Nawet jeśli zdarzy się jakaś obsługowa „wpadka” (a to w dużych organizacjach nieuniknione) będą w stanie odpowiednio i szybko na nią zareagować. Dzięki sprawnie działającemu systemowi opartemu o predykcję, reakcja może być tak szybka, że konsument nawet nie zdąży pomyśleć o poszukiwaniach konkurencyjnego dostawcy.