Znalezienie kompromisu między maksymalizowaniem zysków i obniżaniem kosztów nie jest prostym zadaniem dla marketerów planujących kampanie marketingowe. Dla ROI kampanii kluczowy jest wybór właściwej grupy, do której chcemy skierować ofertę. Z pomocą przychodzi uplift modeling, które bada prawdopodobieństwo dokonania zakupu przez klientów.
Środek lata. Trochę „martwy” sezon. Rozmowy w dziale marketingu jednego z największych retailerów w Polsce dotyczą nie tylko wrażeń z urlopów, ale także tego jak choć trochę „rozruszać” sprzedaż. Jeden z pracowników sugeruje przeprowadzenie kampanii smsowej. Jest baza konsumentów, którą można skomunikować. Jest nawet dosyć atrakcyjna oferta, o której można napisać. Nic tylko wysyłać. Pojawia się jednak problem. Zbliża się koniec roku finansowego i w budżecie nie zostało już zbyt wiele środków. Wystarczy, żeby przeprowadzić wysyłkę do co najwyżej jednej piątej bazy. Entuzjazm nieco opada – fajerwerków nie będzie. Co jednak zrobić, żeby jak najlepiej wykorzystać ograniczony budżet i zmaksymalizować szanse na osiągnięcie zauważalnego efektu? Ktoś wpada na pomysł, żeby zwrócić się do zaprzyjaźnionych konsultantów data science. Czasu jest mało i trzeba działać szybko, ale doświadczony zespół Data Science Logic podejmuje wyzwanie.
Czy można przewidzieć zakup?
W oparciu o blisko 200 zmiennych opisujących konsumentów w bazie w zakresie historii transakcji, kupowanego asortymentu, wrażliwości na cenę, skłonności do kupowania online, interakcji z komunikacją marketingową, wizyt na stronie www retailera, analitycy budują model scoringowy przewidujący prawdopodobieństwo zainteresowania promowanym asortymentem dla każdego konsumenta, który mógłby zostać potencjalnie skomunikowany. Modele takie nazywane są w świecie data science product propensity models, likelihood to buy models lub response models.
Dostępny budżet podzielony zostanie na dwie części. Połowa konsumentów zostanie wyselekcjonowana dotychczasowym sposobem. Drugą część stanowić będzie 10% najbardziej zainteresowanych konsumentów według predykcji modelu. Dodatkowo spośród wszystkich zakwalifikowanych do wysyłki wylosowana zostanie grupa kontrolna, która nie otrzyma wiadomości. Taki podział pozwala na pomiar skuteczności dwóch metod targetowania oraz efektu samej komunikacji.
Wyniki: konwersja w grupie wybranej przez model blisko 3-krotnie wyższa niż w grupie wytypowanej dotychczasową metodą opartą o kryteria ekspercie. Rezultaty mówią same za siebie. Data science zwycięża. Czyżby?
Czy na pewno patrzymy na właściwy wskaźnik?
Z porównania konwersji wynika, że model poprawnie przewidział grupę konsumentów ponadprzeciętnie zainteresowanych zakupem. Czy jednak nie byli to klienci, którzy i tak dokonaliby transakcji nawet bez smsa? Jaki był faktyczny wpływ wysyłki na ich skłonność do zakupu? Odpowiedzi na te pytania możemy znaleźć, dokonując porównania z grupą kontrolną losowo wyłączoną z komunikacji. Wynika z niego, że różnica pomiędzy konwersją w całej grupie komunikowanej a konwersją w grupie kontrolnej wyniosła około 1,8 punktu procentowego. W grupie wytypowanej przez model natomiast około 2 p.proc. Różnica jest więc wciąż na korzyść modelu, ale nie jest już tak spektakularna. Oznacza to, że część konsumentów wskazanych przez model była wystarczająco zainteresowana zakupem już przed komunikacją i nie było potrzeby dodatkowo ich stymulować. W jaki więc sposób możemy sklasyfikować konsumentów pod kątem ich spodziewanej reakcji na komunikację marketingową?
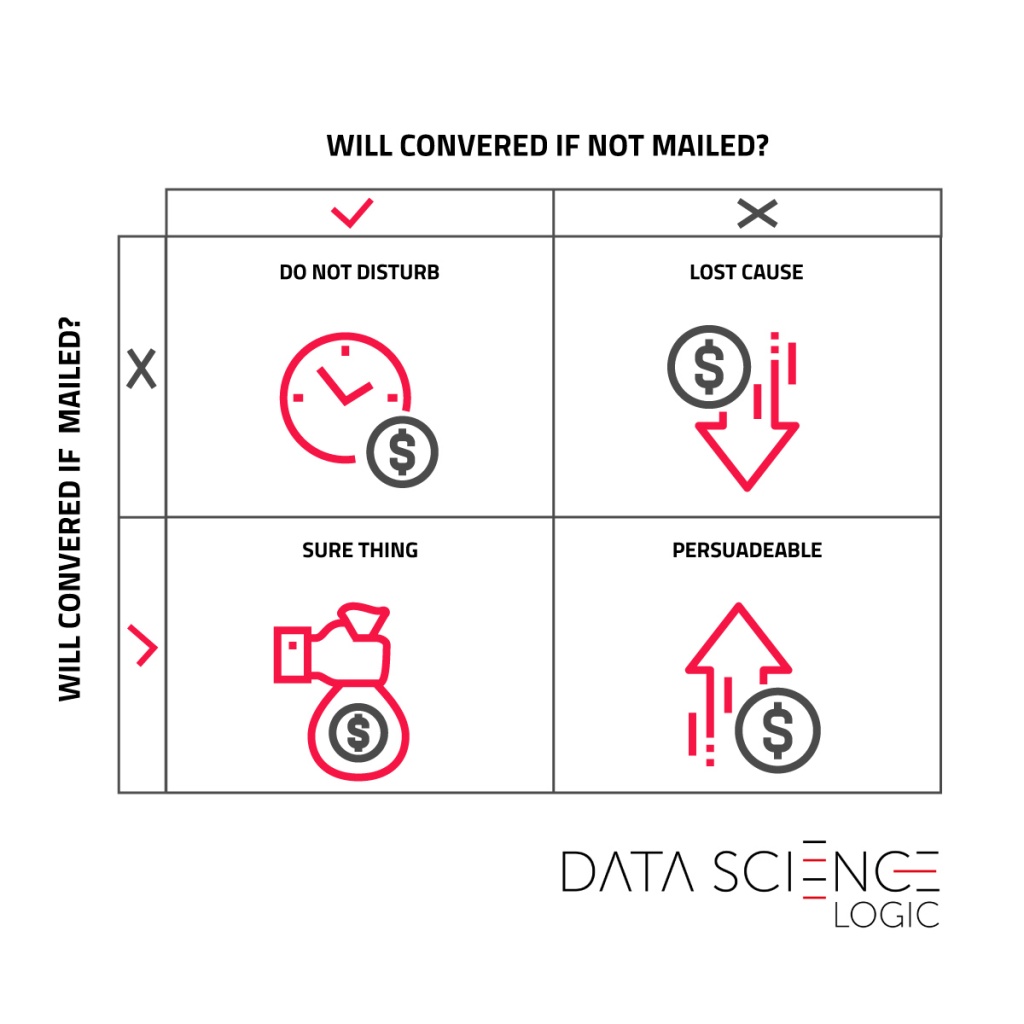
Lewy górny kwadrat to grupa ‘Do not disturb’, którzy byliby zainteresowani transakcją, ale zaniepokojeni niechcianą komunikacją rezygnują z zakupu. Część ‘Lost cause’ to konsumenci, których nie jesteśmy w stanie przekonać do zakupu, nawet przy pomocy planowanej kampanii. Grupa ‘Sure thing’ to ludzie chętni do zakupu nawet bez komunikacji. Wreszcie prawy dolny kwadrat to ‘Persuadable’ czyli grupa, która nie jest jeszcze przekonana do zakupu i bodziec w postaci kampanii jest w stanie wpłynąć na decyzję. Mamy więc jedną grupę, na którą opłaca się oddziaływać komunikacją oraz trzy, do których nie warto kierować wysyłek. Jak jednak przewidzieć, kto jest w tej opłacalnej grupie?
Uplift modeling
Z pomocą ponownie przychodzi data science. Możliwe jest zbudowanie modelu, który przewiduje zmianę skłonności do zakupu pod wpływem komunikacji. Na podstawie danych zebranych przy pierwszej wysyłce, budujemy model uplift, który dopasuje konsumentów do odpowiednich grup. Obserwujemy wzrost uplift’u kamapnii – o prawie 0,4 p.p. w porównaniu do grupy wytypowanej przez model responsu. Pozornie niewiele, jednak przy odpowiedniej skali bazy, zyskujemy znaczącą ilość dodatkowych transakcji. W stosunku do poprzednio stosowanych metod selekcji model responsu wygenerował 10% więcej dodatkowych sprzedaży, a najbardziej zaawansowany model uplift aż prawie 30% więcej.
Tym, co kupujemy, wydając budżet na komunikację do konsumentów są tak naprawdę dodatkowe konwersje, których nie osiągnęlibyśmy gdyby nie kampania. Odpowiednio dobierając komunikowaną grupę, możemy z takim samym budżetem wygenerować znacząco więcej inkrementalnych zakupów. Uplift modeling, inaczej modelowanie predykcyjne dostępne wśród narzędzi data scientists może być tutaj istotną pomocą.